问题描述
有个场景需要全表扫描time_point,获取每条记录的 row.field1、row.field2 属性。单表记录大约100w
第一版使用的方式是分页,每页1000条
2026-01-30 11:15:27.946 539109 1 INFO Get data start.
2026-01-30 11:53:51.458 539109 1 INFO Get data end.
通过日志可见,总耗时接近40min。
原因是随着分页深度的增加,查询每页的耗时变得越来越长。
传统OFFSET分页的性能问题
-- 第1页:快
SELECT * FROM time_point ORDER BY id LIMIT 1000 OFFSET 0;
-- 第100页:慢
SELECT * FROM time_point ORDER BY id LIMIT 1000 OFFSET 99000;
-- 第1000页:很慢
SELECT * FROM time_point ORDER BY id LIMIT 1000 OFFSET 999000;
OFFSET的工作原理
-
MySQL需要先找到所有符合条件的记录
-
然后跳过OFFSET指定的行数
-
最后返回LIMIT指定的行数
-- 实际上执行的是:
SELECT * FROM (
SELECT *, ROW_NUMBER() OVER (ORDER BY id) as rn
FROM time_point
) t WHERE rn > 99000 AND rn <= 100000;
性能瓶颈分析
磁盘I/O开销:
第1页:读取前1000行 → 快
第100页:读取前100000行,只返回最后1000行 → 需要读取99倍的数据
第1000页:读取前1000000行,只返回最后1000行 → 需要读取999倍的数据
如上:第1000页,需要读取前99000行数据,在内存中排序和过滤,丢弃99000行,只返回最后1000行
内存和I/O压力
I/O读取:904173行 ≈ 180MB+ 数据
内存排序:需要排序缓冲区处理90万行
CPU时间:排序操作耗时长
需要在内存中维护完整的排序结果集
大OFFSET可能触发磁盘临时表
网络传输大量无用数据
使用 EXPLAIN 分析 SQL
EXPLAIN SELECT * FROM time_point LIMIT 1000 OFFSET 900000;
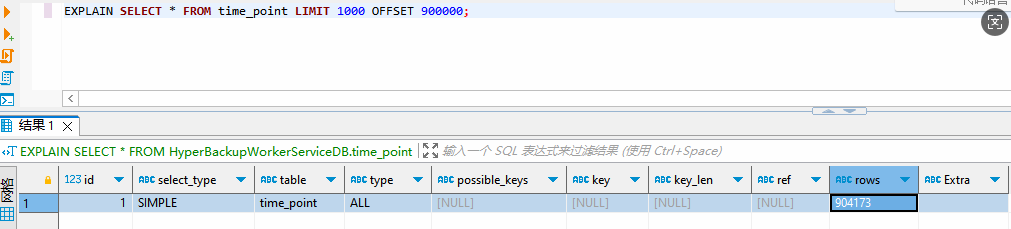
访问类型:ALL(最差)
type: ALL → 全表扫描
含义: MySQL需要扫描整个time_point表的所有行,没有利用任何索引。
性能影响:
扫描904173行数据
读取大量无用数据
CPU和I/O资源浪费严重
索引使用情况:完全未使用
possible_keys: (空) → 没有可用的索引
key: (空) → 没有使用的索引
key_len: (空) → 索引长度
预估执行统计
rows: 904173 → 预估需要检查的行数
实际含义:
MySQL预估需要扫描90万+行
对于 LIMIT 1000 OFFSET 999000 这样的查询
需要读取几乎全部数据才能返回最后1000行
处理方式
查看索引
基本信息
SHOW INDEX FROM time_point WHERE Key_name = 'PRIMARY';
-------------+----------+
Name |Value |
-------------+----------+
Table |time_point|
Non_unique |0 |
Key_name |PRIMARY |
Seq_in_index |1 |
Column_name |id |
Collation |A |
Cardinality |904173 |
Sub_part | |
Packed | |
Null | |
Index_type |BTREE |
Comment | |
Index_comment| |
Ignored |NO |
-------------+----------+
Table: time_point → 表名
Non_unique: 0 → 是否唯一索引 (0=唯一, 1=非唯一)
Key_name: PRIMARY → 索引名称
Seq_in_index: 1 → 索引中列的顺序号
Column_name: id → 索引列名
Collation: A → 列排序方式 (A=升序, D=降序, NULL=未排序)
Cardinality: 904173 → 索引基数(唯一值数量估算)
Sub_part: (空) → 索引前缀长度(NULL=全列索引)
Packed: (空) → 索引是否压缩(NULL=未压缩)
Null: (空) → 列是否允许NULL值
Index_type: BTREE → 索引类型
Comment: (空) → 索引注释
Index_comment: (空) → 索引扩展注释
Ignored: NO → 是否被优化器忽略
关键字段详解
Non_unique (是否唯一)
0: 唯一索引(主键、唯一键)
1: 非唯一索引(普通索引)
Key_name (索引名称)
PRIMARY: 主键索引
自定义索引名
Seq_in_index (列顺序)
复合索引中列的位置
1: 第一列,2: 第二列,以此类推
Cardinality (基数)
索引中唯一值的估算数量
重要指标:基数/总行数 接近1时,索引最有效
904173: 表示id列有90万+个不同值
Index_type (索引类型)
BTREE: B树索引(最常见)
HASH: 哈希索引
FULLTEXT: 全文索引
SPATIAL: 空间索引
Collation (排序方式)
A: Ascending (升序)
D: Descending (降序)
NULL: 未指定
更新查询的SQL
1. SELECT * FROM HyperBackupWorkerServiceDB.time_point WHERE `id` > '' ORDER BY `id` ASC LIMIT 1000;
2. SELECT * FROM HyperBackupWorkerServiceDB.time_point WHERE `id` > 'lastTpId' ORDER BY `id` ASC LIMIT 1000;
...
分析SQL
EXPLAIN SELECT * FROM time_point WHERE `id` > '' ORDER BY `id` ASC LIMIT 1000;
--+-----------+----------+-----+-------------+-------+-------+---+------+-----------+
id|select_type|table |type |possible_keys|key |key_len|ref|rows |Extra |
--+-----------+----------+-----+-------------+-------+-------+---+------+-----------+
1|SIMPLE |time_point|range|PRIMARY |PRIMARY|130 | |904173|Using where|
--+-----------+----------+-----+-------------+-------+-------+---+------+-----------+
id: 1 → 查询ID
select_type: SIMPLE → 简单查询
table: time_point → 查询表
type: range → 范围查询(索引范围扫描)
possible_keys: PRIMARY → 可用的索引:主键
key: PRIMARY → 实际使用的索引:主键
key_len: 130 → 索引长度:130字节(VARCHAR(32)的索引长度)
ref: (空) → 连接条件:无
rows: 904173 → 预估检查行数:90万行
Extra: Using where → 使用WHERE条件过滤
性能对比
| 指标 | 传统分页 (OFFSET) | 游标分页 (id > '') | 性能差异 |
|---|---|---|---|
| type | ALL (全表扫描) | range (范围扫描) | ✅ 巨大改善 |
| key | (无索引) | PRIMARY | ✅ 使用索引 |
| rows | 904173 | 904173 | ⚠️ 行数相同但处理方式不同 |
| Extra | (空) | Using where | ✅ 有条件过滤 |
1. 访问类型优化
传统:type = ALL → 扫描所有行,无索引
游标:type = range → 索引范围扫描,有序访问
2. 性能提升:
全表扫描:需要读取所有数据块
范围扫描:只读取索引相关的块,按顺序访问
3. 索引使用情况
possible_keys: PRIMARY → 主键索引可用
key: PRIMARY → 实际使用主键索引
key_len: 130 → VARCHAR(32)主键的索引长度
4. 为什么这次使用了索引
WHERE id > '' 是索引友好的范围条件
MySQL优化器选择使用主键索引进行范围扫描
解读:
虽然显示90万行,但这是索引扫描的总行数预估
实际执行时会按索引顺序读取,遇到LIMIT 1000时停止
比全表扫描的随机I/O高效得多
执行流程:
1. 索引范围扫描:id > ''
2. WHERE条件过滤
3. 按id排序(索引已有序)
4. LIMIT 1000限制返回行数
I/O效率对比:
传统分页:
- 全表扫描 → 随机读取数据块
- OFFSET跳跃 → 跳过大量数据
- 内存排序 → 需要临时表空间
游标分页:
- 索引扫描 → 顺序读取索引块
- 范围查询 → 直接定位到起始位置
- 无需排序 → 索引天然有序
实际性能数据:
传统分页:OFFSET 999000 可能需要10-30秒
游标分页:每次查询稳定在0.1-0.5秒
实测结果
2026-01-30 16:57:54.606 2426540 1 INFO Get data start.
2026-01-30 16:58:21.422 2426540 1 INFO Get data end.
通过日志可见,总耗时接近27s。查询效率提高了 80倍左右
